
The meaning of ‘footy’, like ‘curry’, is heavily dependent on context. Sure, there may be a shared essence, the consistency of the sauce, the rice, the contact of foot against ball, but the details are so varied and so specific, going beyond nationality down to the level of regional cultures, local histories, so as to make one version strange, foreign to those who enjoy another, meanings divided by borders, not of nations, but of practices, ingredients, movements. As a child, I confidently declared that I did not like curry, to which my dad replied, “But that’s impossible: there are too many curries, and they’re too different from each other, to make a blanket statement about all of them. You don’t actually know whether you like curry.” I should have specified that I did not like his curry. Thankfully, my palate has since matured, and I now enjoy a wide variety of curries: red and green from Thailand, vindaloo and rogan josh from India, katsudon from Japan, etc. Footy, on the other hand, was not even a concept that occurred to me in my youth. Football was a sport in which the only players who touched the ball with their feet were two specialists who spent a grand total of maybe 10 minutes on the field per game, but footy meant nothing to me. Not until I arrived in Australia was I able to attach ‘footy’ to something that existed in external reality. And as with any new knowledge, my initial conception of footy was shallow, only encompassing the first instance that I encountered: Aussie rules football. Only with time, and cultural exchange, have I learned that there are those who refer to rugby and even soccer (referred to here as such to differentiate it from all the other footballs) as ‘footy’. An Englishman, Queenslander, and Victorian are capable of speaking the same language without understanding a single word.

I’ve lived in Melbourne, Victoria for over four years, and here ‘footy’ means Aussie rules football. I have vague memories of occasionally catching a game at odd hours as a child, perhaps the result of a young ESPN desperate to fill airtime, but the only aspect of the game that stuck was the referees shooting finger guns in the most-serious way possible whenever a team scored. Over the last few years, however, I’ve attended and watched enough matches and had enough conversations with footy fans to get a sense of the game, its rules, and a genuine appreciation for a sport that combines the dynamic action of American football with the uninterrupted flow of soccer. One traditional fan activity that intrigued me was the office footy tipping competition. Like the American practice of filling out a March Madness bracket, a group of coworkers pay a flat entrance fee, then compete to see who can more-accurately predict the winners of Australian Football League (AFL) matches, with the winner taking the pot. Predictions are ‘tips’, and to make a prediction is ‘to tip’. I didn’t participate in such competitions for the first few seasons I lived in Australia, because I didn’t know enough about the sport to have any confidence in my ability to pick winners and losers. Last year, however, I started studying machine learning in my free time and, searching of an engaging — but light — practice project, I thought it might be fun to use data in order to teach a computer predict AFL match results for me. More importantly, I found the idea of the ignorant American rocking up and, like the scrawny, awkward nerd doing physics calculations in order to hit the game-deciding home run, winning the office footy tipping competition too amusing. I had to at least try.
I spent months researching machine-learning methods, especially for time-series data, which presented challenges well beyond classifying irises or predicting who would survive the Titanic; reading papers on applying machine learning to sports; and working on my own models. I remember the irrepressible excitement at reaching almost 80% accuracy on my validation data set, which was the 2016 season. I also remember the crushing despair that came from realising that my recent performance gains had been due to a coding error that resulted in the validation data being mixed in with the training data. Obviously, it’s much easier to predict the results of matches that you’ve already seen. Despite the setbacks, the newb mistakes, the weekends lost to getting Keras and Vowpal Wabbit models to just freaking pickle already, by mid-March I had a model that fed AFL data into a weighted ensemble of a multi-layer recurrent neural network (RNN) classifier, Adaboost classifier, Gradient Boost classifier, Random Forest classifier, Vowpal Wabbit classifier, and XGBoost classifier.
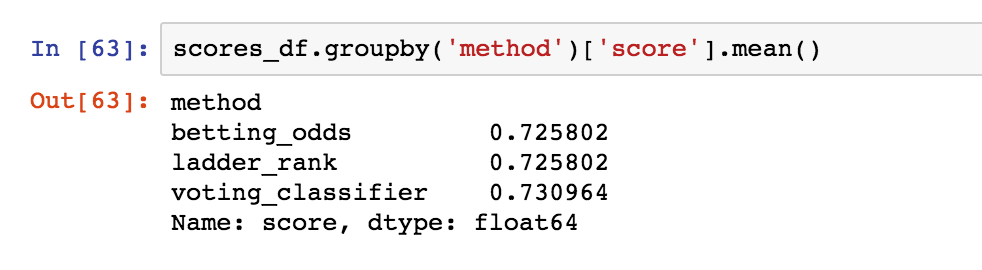 Jupyter notebook output from a test run: tipping accuracies of betting odds, tipping higher-ranked teams, and my machine-learning model.
Jupyter notebook output from a test run: tipping accuracies of betting odds, tipping higher-ranked teams, and my machine-learning model.
In anticipation of the 2018 AFL season, I ran a test that covered 2012 (when the AFL expanded to its current number of teams) to 2017, and my model achieved an overall accuracy ~0.5**% **higher than that of the betting odds.
I dubbed the app that runs my model Footy Tipper. Over the preceding six months, I had learned a lot about footy, machine learning, data science, and even web development, and I was ready to out-tip my coworkers to glory.
Unfortunately, this being my first big project, I made a number of methodological and architectural mistakes that go well beyond the errant slicing of arrays, and I hope to rectify them for Footy Tipper 2.0.
-
From the beginning, I was impatient to get to the good stuff, skipping the kind of exploratory data analysis that could have informed the development of my prediction model and given me insight into which ideas were worth pursuing (rather than just throwing all the data I had at a handful of models).
-
Another consequence of my impatience was my going straight to working with “the best algorithm”, which, after reading about forecasting models, seemed to be a recurrent neural network (RNN). Only later, as I started to build an ensemble model, did I discover that there were algorithms that were simpler, quicker to train, and capable of achieving comparable performance to my multi-layered RNN.
-
I’ve learned a lot about programming over the past year, the principles of Object-Oriented Programming (OOP) in particular. I now realise that development-by-messy-scripts that are later turned into classes without a clear purpose beyond “Well, I guess it can go here” severely hindered my ability to experiment and test out ideas, because I got really hairy bugs in my pipeline every time I made the smallest change to the shape of my data.
-
I was too busy with the technical details to be creative, but ‘Footy Tipper’ is a particularly uninspired name. I didn’t spend four years and 55-credits’ worth of class time earning a B.A. in English literature with a specialisation in creative writing, eventually graduating with departmental honours, just to give my machine-learning-based app such a literal name. There’s not even a literary reference in it. I can do better.
Despite these missteps, and an embarrassingly brutal first half of the season in which, at my nadir, I fell to 11th place out of 15 and a full five tips behind the leader, I’m currently in 2nd place in the office footy tipping competition and only missing out on the lead from the tiebreaker. Not exactly worthy of glory, but not bad, within shouting distance of glory with four rounds to play.

Looking forward, I’m going to take a more-methodical approach to creating my next model, exploring the data a little more and starting with basic models before testing the performance of more complicated ones. There are too many things that I want to do differently to make tweaking my current model and app a practical solution, but there is a lot of code for data cleaning and transformation that I want to reuse, so I’m working from the same codebase, but with the goal of rebuilding both the model and app from scratch. So, for my next post, I will begin my journey of data-science renewal by analysing simple heuristics for footy tipping that aren’t based on statistical or machine-learning models in order to establish a benchmark against which to judge the performance of any future models I develop. Because if I can’t consistently beat tippers who just look up the favourites in the morning paper, what am I doing with all this time and effort spent?